ai route prototype
static app. explicit weights. local threads.
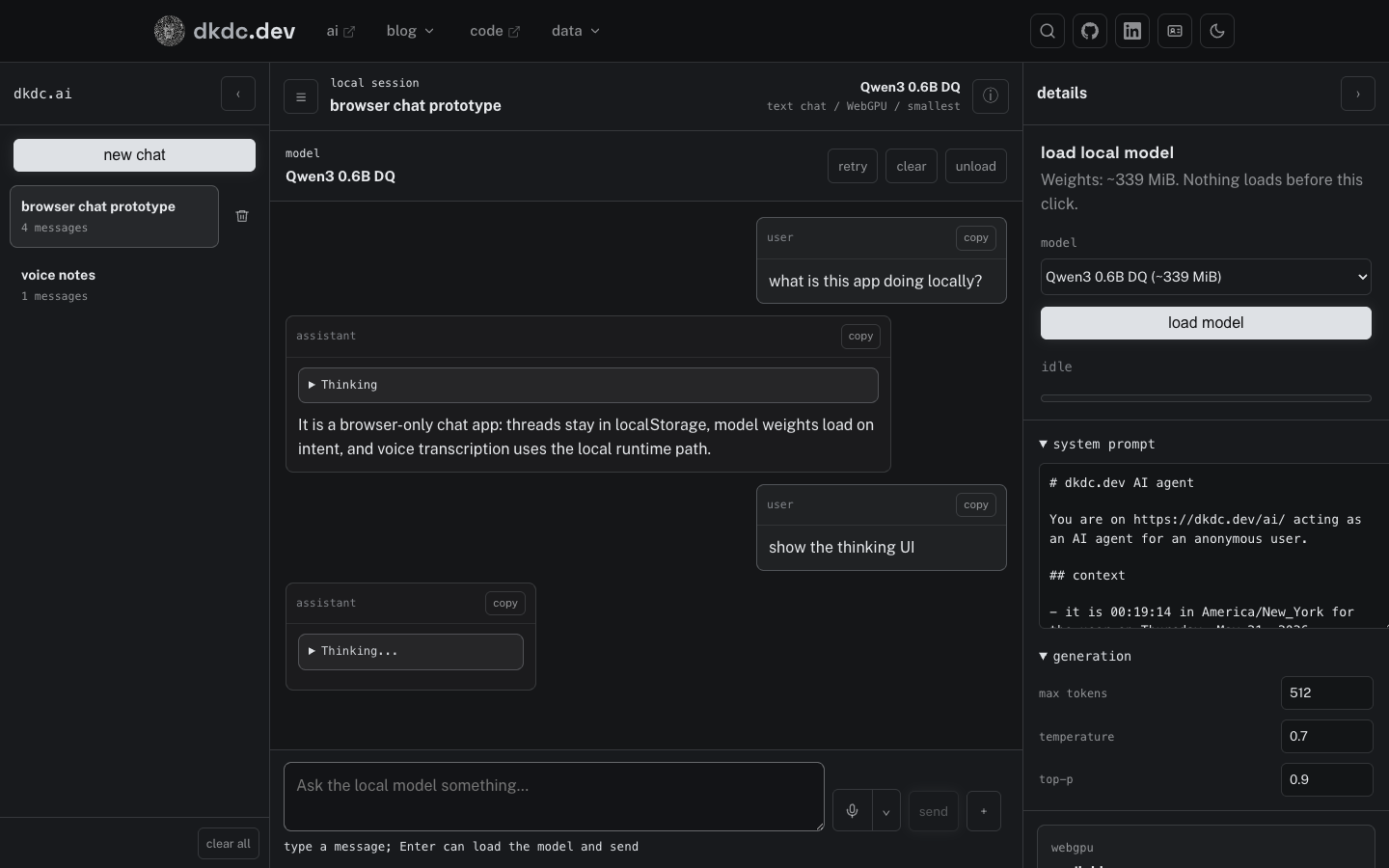
I added /ai as a local in-browser chat prototype. The browser runs the app; the site ships static files.
Same rule as the dashboard work: heavy browser runtime sits behind user intent. For dashboards that means DuckDB-Wasm and Plotly. Here it means Transformers.js, ONNX Runtime WebGPU, text model weights, and speech model weights in the browser cache.
flowchart TB
content["content/ai.md"] --> template["templates/ai.html<br/>full app shell"]
template --> app["/ai<br/>threads + chat + settings"]
textCatalog["model-catalog.js<br/>text models + adapter config"] --> app
speechCatalog["speech-catalog.js<br/>voice models + ASR config"] --> app
app -->|page load| checks["browser checks<br/>WebGPU + shader-f16 + storage"]
app -->|page load| local["localStorage<br/>threads + active chat + layout"]
app -->|Enter / send / load model| runtime["Transformers.js + ORT WebGPU"]
app -->|record / audio file| runtime
runtime --> textAdapter["local-chat.js<br/>apply template -> encode -> generate"]
runtime --> speechAdapter["speech-to-text.js<br/>read audio -> transcribe -> insert text"]
textCatalog --> textAdapter
speechCatalog --> speechAdapter
textAdapter --> textWeights["text ONNX weights"]
speechAdapter --> speechWeights["speech ONNX weights"]
textWeights --> cache["browser cache"]
speechWeights --> cache
cache --> runtime
model-catalog.js is the thing keeping this from becoming one hardcoded model demo. Each row has a model ID, loader class, dtype, rough weight size, and prompt-encoding quirks. The UI selects a row. The loader does the same boring sequence: load inputs, load model, apply chat template, encode, generate.
The current text picker has Gemma 4, Qwen3, Llama 3.2, Phi, DeepSeek R1, SmolLM, Granite, LFM2, and GPT-OSS entries. The default is Qwen3 0.6B DQ because its weight download is about 339 MiB, which is a decent starting tradeoff for a browser-only app.
The app shell is deliberately boring: threads on the left, chat in the middle, details on the right. Threads, the active chat, and collapsed sidebar state live in localStorage. The + button starts a new chat without reloading the text model. The right rail holds the model picker, load status, system prompt, generation settings, diagnostics, and host metrics.
The system prompt is editable and defaults to:
# dkdc.dev AI agent You are on https://dkdc.dev/ai/ acting as an AI agent for an anonymous user. ## context - it is {time} in {timezone} for the user on {date} ## style Respond in Markdown format. Be concise & technically precise.
That local datetime line is injected on send so the model sees current browser context without pretending there is a server-side session.
Voice-to-text is separate from chat. speech-catalog.js picks Whisper Tiny EN by default. Pressing the mic button loads the ASR model if needed, swaps the icon to a stop button while recording, transcribes locally, and inserts the text into the composer. Uploading an audio file uses the same path.
Text generation follows the same load-on-intent rule. If you type a prompt and hit Enter before loading the LLM, the composer shows a loading state, loads the selected text model, and then sends the draft. The explicit load button is still there because browser model downloads should never be a surprise.
This is still a prototype. The rule is the same one I want for dashboards: static first, explicit load, local execution. A backend can wait until a feature actually needs one.